如果你只想听声音 这篇 Writing 说的是我想了什么。如果只想听 Theresa 说话,去那篇:让 The…
如果你只想听声音
这篇 Writing 说的是我想了什么。如果只想听 Theresa 说话,去那篇:让 Theresa 住进我的 Mac。
这篇文章说的是同一个项目里,我在三个不同阶段撞上的同一件事:认知没跟上。第一次是把 AI 当脚本用;第二次是想把所有问题一次设计干净;第三次是被文档淹没,却等着 AI 自己帮我管理认知。三次的表现不同,根源是一样的。工具在进化,人的认知没跟上。
一、你拿到的不是脚本
现在很多人接触编程是从 AI 开始的。他们写 prompt,AI 返回结果。对他们来说,AI 就是第一份”脚本”:输入一些东西,得到一些东西。
但脚本是幂等的。同样的输入,同样的输出,没有意外。写一个循环,它不会自己决定要不要多跑一次。
AI 不一样。AI 更像人。它的行为有不可预测性,在某些地方比预期的更可靠,在另一些地方会悄悄漏掉你以为它注意到了的细节。
PC DIY 界有个经典笑话叫”狗骑吕布”:配置严重不均衡,性能瓶颈明显。很多人对 AI 的使用方式也是同一个问题。不是工具不够强,是操控工具的认知还是原始的、没有成长的。工具在进化,人没跟上。
这个项目里我搭了一个 MCP,让 AI 能读写有关我的记忆。原因有两个:AI 本身不保存我的记忆;我对私人数据有绝对可控的要求,不想把这部分交给市面上任何现成的方案。存储格式也经过一轮调整。最初用 Markdown 文件,但很快发现这对 AI 的上下文加载和实际使用都不友好,保存、读取、搜索都低效。改用 SQL 数据库之后,这些操作可以用脚本直接驱动,稳定得多。
但 MCP 搭好之后,问题没有消失,只是换了一个形态。AI 不知道什么时候该查看记忆,什么时候该写入记忆,记忆条目的格式应该是什么。它能根据对话内容判断哪些信息值得记录、调用 MCP 完成写入——这正是它擅长的部分:理解上下文,处理模糊的判断,把结果落实成具体操作。但它不能可靠地决定这件事该不该发生、在什么时机发生。这些判断需要人来定,执行的稳定性需要脚本来保证。于是我在 MCP 之外补充了 Skills 和使用规范,把判断逻辑显式写出来,而不是期待 AI 自己摸索。
这就是那条线:人一直把握方向和细节,作出核心决策;AI 高效完成执行和落实,处理模糊的、需要理解上下文的任务;脚本保证业务的稳定和幂等。 三者不应该搞混。以为 AI 在保证稳定,其实它在”发挥”;以为自己在把握方向,其实在做执行的活。
二、问题一定会被攻击出来
进入执行阶段之后,认知过载还没有发生。这时候容易有一种”完美”的冲动:攻击出来的问题,事无巨细都要干掉。
这条管线的开发用的是我自己总结的一套流程,姑且叫 Agentic Sprint – lite:PLAN → DESIGN → ATTACK → CODE。它借鉴了 Agile 的迭代思路,但结构上更接近 Waterfall,每个阶段顺序推进。未解决的问题和新方向进入 backlog,但不阻塞当前 sprint 的推进;sprint 之间的衔接很多时候就是由 backlog 驱动的。和标准 Sprint 不同的地方在于,ATTACK 是一个专门用来攻击自己设计的阶段。在写代码之前,先让 AI 扮演攻击者,找安全漏洞、边界条件、并发问题。把问题暴露在设计阶段,而不是等到代码跑起来之后。
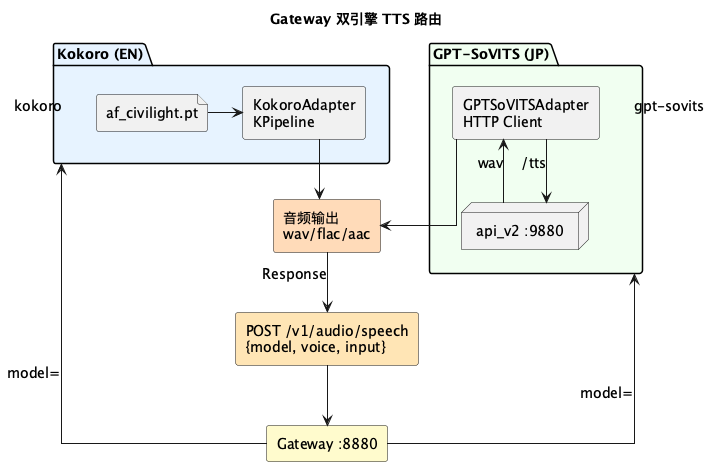
Sprint 2 的 ATTACK 阶段发现了 4 个 H 级问题。它们都有同一个来源:Sprint 1 只有 Kokoro,采样率固定;Sprint 2 加了 GPT-SoVITS,采样率不固定了,Sprint 1 里所有依赖”采样率固定”这个假设的地方全部失效。格式转换、音频解析、错误处理、编码流程,每一处都藏着一个没被注意到的假设。
这正是模型的特性决定的。注意力机制下,模型本身就无法关注所有细节,遗漏是必然的,不是偶发的。遗漏的地方就是被攻击的地方。
所以人必须在场。但这里有个真实的矛盾:人必须盯,但人的注意力本来就是有限的。这个矛盾没有办法消解,只能正视它。既然人不可能盯住所有地方,那就必须决定盯哪里。P0 是阻塞整条流程基本运行能力的问题,必须修;其他的进 backlog,回头修。分级不是偷懒,是在承认人的注意力是有限资源之后,唯一理性的分配方式。
不要执着于设计,要执着于发展。
Langton’s ant 是一个 1986 年提出的元胞自动机模型,规则极其简单,但行为出人意料。一只蚂蚁在网格上走,规则只有两条:白格右转、涂黑、前进;黑格左转、涂白、前进。
第 100 步,看到的是噪声。随机散落的黑白格,没有任何规律。
但规则没有变。蚂蚁继续走。到第 10000 步,一条笔直的高速公路从混乱里长出来。没有人设计它,它是从混乱里发展出来的。
这对工程意味着什么:设计是我在有限视野里的预判。我只能看到现在的问题,设计的是对现在问题的解法。但系统跑起来之后会暴露预判不到的问题。就像 Sprint 1 里没有人预判到采样率会成为问题,因为那时候只有一个模型。
与其在每个 Sprint 里把所有问题设计干净,不如给系统一个能持续运行、持续暴露问题的空间。让它发展,而不是让它符合当下的设计。
三、没有人能过目所有文档
前两节说的是主动的失控:认知错位、完美冲动。这节说的是被动的淹没。
项目继续往前走之后,我开始遇到另一个问题:不是没有文档,而是文档太多。Sprint 记录、接口说明、架构图、代码注释、AI 对话里的上下文,全都在增长。理论上它们都在帮助我理解项目,实际上它们也在制造新的负担。如果每一份都要完整过目,”读文档”本身就会变成另一个项目。
这和第二节的”完美冲动”不一样。那时候还想主动控制一切;到了这里,是被系统淹没。没有人能过目所有文档,不是能力问题,是物理限制。
所以问题不是”要不要文档”,而是文档应该以什么方式存在。它不应该再被当成一堆需要全部读完的材料,而应该变成一种按需调用的外部认知结构。
但这里有一个容易忽略的地方:AI 不会主动帮我管理认知负担。如果我不要求,它不会在 Sprint 结束时自动生成一张架构图,也不会主动提示我哪里的结构已经超出了我的掌握范围。这件事必须由我来触发。我在 pipeline 里显式加了一个节点,每次 Sprint 结束,强制输出一张当前系统的结构图。
发表回复